A FSharp implementation of Huffman compression algorithm
Implementating Huffman algorithm is a good practice to progress in algorithms and is a good opportunity to train on working methods such as TDD.
This article is based on the gist I wrote to train me.
Huffman compression method can be decomposed in 3 steps:
- computing a dictionary with frequency of occurrences
- building a tree representing frequencies and associated path
- storage of tree and path of each occurrence bit per bit
In next examples, we will work on the string “aaabbffppppeee kk aa”
Computing frequencies
At first, we can imagine a dictionary of char * int containing each char frequency. It don’t like to work with chars when I implement binary data traitment algorithms. So, I created an empty function getting (byte * int) list
let getFrequencies (l:byte list) : (byte*int) list =
failwith "not implemented"Then I wrote a test I executed each time I could compile:
[<Test>]
member ``when is``.``computing frequencies`` () =
let f =
"aaabbffppppeee kk aa"
|> strToBytes
|> getFrequencies
// converting bytes to chars to make tests writing easier
|> List.map (fun (b,c) -> char b , c)
|> dict
Assert.AreEqual(f.Item 'a', 5)
Assert.AreEqual(f.Item 'b', 2)
Assert.AreEqual(f.Item 'f', 2)
Assert.AreEqual(f.Item 'p', 4)
Assert.AreEqual(f.Item 'e', 3)
Assert.AreEqual(f.Item 'k', 2)A simple function to work with bytes list could be:
let getFrequencies (l:byte list) =
l |> Seq.groupBy(fun c -> c)
|> Seq.map (fun (c,l) -> c, (List.ofSeq l).Length)
|> Seq.toListI did want to try compression on real files, so I couldn’t load entire content in a byte list. Next function is computing frequencies from a seekable stream.
let getFrequencies' (stream:Stream) =
let rec loop (acc:(byte*int) list) =
let i = stream.ReadByte()
if i < 0
then acc
else
let b = byte i
match acc |> List.tryFind(fun (v,_) -> v = b) with
| Some (_,c) ->
acc
|> List.filter(fun (v,_) -> v <> b)
|> List.append [(b, (c+1))]
| None -> acc |> List.append [(b, 1)]
|> loop
stream.Position <- 0L
let f = loop []
stream.Position <- 0L
fBuilding the tree
My tree model is simply:
type bit = bool
type path = bit list
type BinaryTreeNode =
| Leaf of byte * frequency:int
| Branch of left:BinaryTreeNode option
* right:BinaryTreeNode option
* frequency:int
member __.Switch(b:bit) =
match __ with
| Branch (_, right, _) when b -> right
| Branch (left, _, _) when not b-> left
| _ -> None
static member Empty = Leaf(0uy,0)
member private __.cost =
lazy
match __ with
| Leaf (_, f) -> f
| Branch(_,_,f) -> f
member __.Cost() = __.cost.Value
type BinaryTree (root:BinaryTreeNode) =
member __.Root with get() = root
member __.GetPath (data:byte) =
let rec scan (node:BinaryTreeNode) (d:byte) (p:path) =
let scanBranch (left:BinaryTreeNode option) (right:BinaryTreeNode option) (cp:path) =
let scanChildren parent v =
match parent with
| Some(Leaf(l,f)) -> scan (Leaf(l,f)) d (cp @ [v])
| Some n -> scan n d (cp @ [v])
| None -> None
scanChildren left false
|> function
| Some r -> Some r
| None -> scanChildren right true
match node with
| Leaf (b,_) when b = data -> Some p
| Leaf _ -> None
| Branch (left, right, _) -> scanBranch left right p
scan root data []
member __.GetByte(p:path) =
let rec loop (bits:path) (current:BinaryTreeNode) =
match bits, current with
| true :: tail, Branch(_, Some r, _) -> loop tail r
| false :: tail, Branch(Some l,_, _) -> loop tail l
| _, Leaf(d, _) -> d
| _ -> failwith "invalid path"
loop p rootThe cost is is representing total occurencies count contained by child branches or leaf. The swith method helps to browse sub branches of a tree node.
When the model is written, we can write tests:
[<Test>]
member __.``checking path consistence`` () =
let tree1 =
"aaabbffppppeee kk aa"
|> strToBytes
|> getFrequencies
|> buildTree
let pa = tree1.GetPath(byte 'a')
let pb = tree1.GetPath(byte 'b')
let pf = tree1.GetPath(byte 'f')
let pp = tree1.GetPath(byte 'p')
let pe = tree1.GetPath(byte 'e')
let pk = tree1.GetPath(byte 'k')
Assert.AreEqual(byte 'a', tree1.GetByte(pa.Value))
Assert.AreEqual(byte 'b', tree1.GetByte(pb.Value))
Assert.AreEqual(byte 'f', tree1.GetByte(pf.Value))
Assert.AreEqual(byte 'p', tree1.GetByte(pp.Value))
Assert.AreEqual(byte 'e', tree1.GetByte(pe.Value))
Assert.AreEqual(byte 'k', tree1.GetByte(pk.Value))After tests writting, we can implement a function populating the tree from frequencies:
let buildTree (frequencies: (byte*int) list) =
let sort (tree:BinaryTreeNode list) =
tree |> List.sortBy (fun i -> i.Cost())
let rec loop (tree:BinaryTreeNode list) =
match sort tree with
| left::right::[] ->
Branch(Some left, Some right, left.Cost() + right.Cost())
| left::right::tail ->
let branch = Branch(Some left, Some right, left.Cost() + right.Cost())
loop (branch :: tail)
| [single] -> single
| [] -> failwith "invalid operation"
frequencies
|> Seq.map Leaf
|> List.ofSeq
|> loop
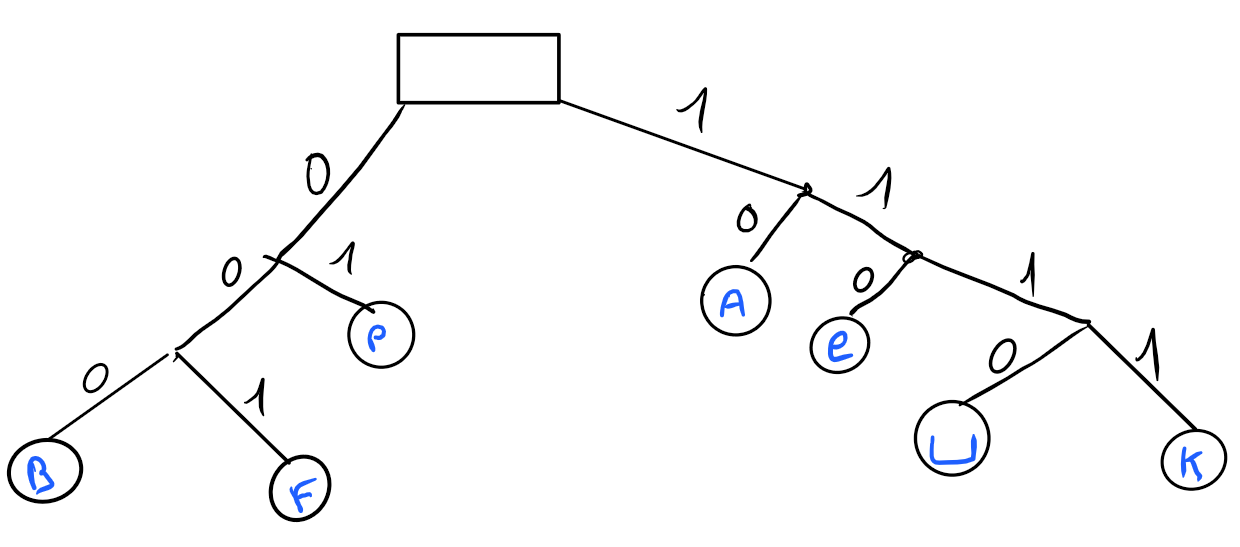
|> BinaryTreeCalculated paths are:
| occurrency | path option | binary | frequency |
|---|---|---|---|
| a | Some({[True;False]}) | 10 | 5 |
| p | Some({[False; True]}) | 01 | 4 |
| e | Some({[True; True; False]}) | 110 | 3 |
| b | Some({[False; False; False]}) | 000 | 2 |
| f | Some({[False; False; True]}) | 001 | 2 |
| k | Some({[True; True; True; True]}) | 1111 | 2 |
| ’ ‘ | Some({[True; True; True; False]}) | 1110 | 2 |
This table is demonstrating that implementation is correct. Occurrences whose frequencies are higher have the shortest paths.
A diagram summarizing this table could be like the following:
Test online to compute a Huffman tree
Try huffman implementation compiled with fable.
| occurrency | binary | frequency |
|---|---|---|
| a | 10 | 5 |
Compression summary
Storage
The occurrency ‘a’ will be coded in 2 bits. We can not write less than 8 bits in a stream. (with the WriteByte method) So I wrote a tiny BitWritter:
type BitWriter(stream:Stream) =
let buffer = ref 0uy
let len = ref 0
let flush() =
while !len < 8 do
buffer := !buffer <<< 1
buffer := !buffer ||| 0uy
len := !len + 1
stream.WriteByte(!buffer)
stream.Flush()
buffer := 0uy
len := 0
let mustFlush() =
!len >= 8
member __.Flush() =
if mustFlush() then flush()
member __.Close() =
if !len > 0 then flush()
member __.Write(b:bit) =
let v = if b then 1uy else 0uy
buffer := ((!buffer) <<< 1) ||| v
len := !len + 1
__.Flush()
member __.Write(bits:bit list) =
for b in bits do __.Write b
interface IDisposable with
member __.Dispose() =
__.Close()The buffer is a simple byte. The write method increases the len and shift bits of buffer. When len is equal to 8 bits, we write the byte in the stream.
To read bit per bit in a stream, I use:
type BitReader(stream:Stream) =
let buffer = ref 0uy
let len = ref 0
let position = ref 0L
let loadBuffer() =
if stream.Position >= stream.Length
then buffer := 0uy
len := 8
let by = stream.ReadByte()
if by = -1
then buffer := 0uy
buffer := byte by
let readBit() =
len := !len - 1
let mask = 1 <<< !len
let v = !buffer &&& (byte mask)
position := !position + 1L
v >= 1uy
let peekBit() =
let mask = 1 <<< (!len - 1)
let v = !buffer &&& (byte mask)
v >= 1uy
member __.End with get() = stream.Position >= stream.Length && !len <= 0
member __.Position with get() = position
member __.Read() =
if __.End
then None
else
if !len <= 0
then loadBuffer()
Some (readBit())
member __.Peek() =
if __.End
then None
else
if !len <= 0
then loadBuffer()
Some (peekBit())Try this implementation on real files using gist